Sora可生成最长60秒的视频,并且在这个过程中,还能够自己切换镜头,甚至给出特写。
以下是视频提示词译文及Sora直接根据提示词英文原文生成的“作品”。
一位时尚的女士走在亮着霓虹灯和广告牌的东京街头。她穿着黑色皮夹克、红色长裙和黑色靴子,手提一只黑色包包。她戴着太阳镜,涂着红色口红。她走路既自信又随意。街道潮湿,地面上的水能够像镜面一样反射色彩斑斓的灯光,路上有很多行人来来往往。

视频来源:OpenAI官网
若非是在Sora介绍下看到这个视频,想必大部分的人都会以为这是由专业团队拍摄剪辑出来的视频吧。在OpenAI的社区中,也出现一些评论,表示被Sora的能力所震撼到,担心Sora会抢走动画师的饭碗。

▲已由机器翻译,来源:community.openai.com
还有一些网友担忧这样逼真的技术会被用来伪造视频,甚至被用来在法庭上作伪证。
▲已由机器翻译,来源:X
其实我在看到视频效果后,也大受震撼。以前:我只相信自己的眼睛。现在:什么是真的?你说什么是真的?!

Sora到底都有什么能力?是否真的危及到了一些行业人员的饭碗?它与其他模型有何不同?
▼Sora与市面上其他视频模型对比
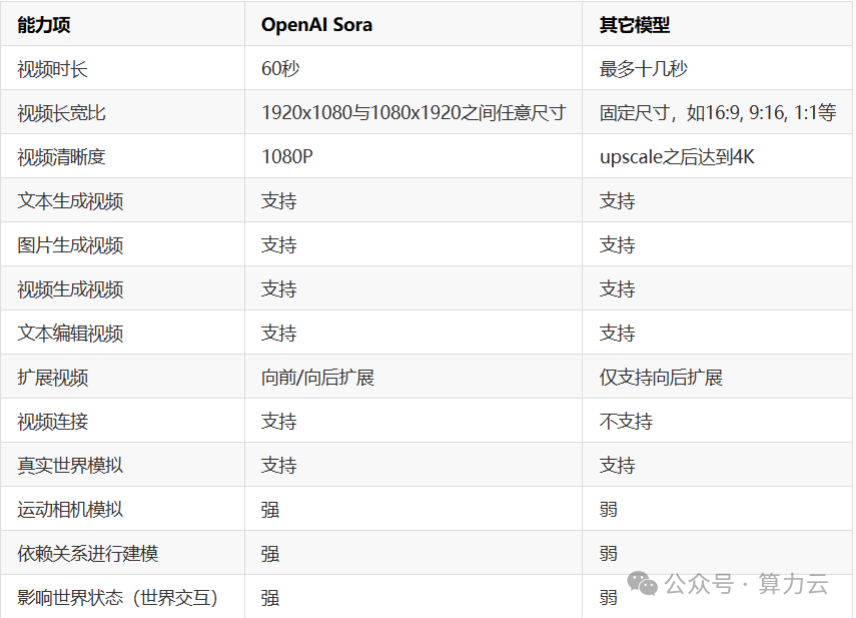
不仅如此,Sora现在可支持人工过程(数字世界模拟),能力项可以说是将市面上其他视频模型压着打了。
Sora能 力 概 述
在OpenAI发布Sora之前,业界基于大模型生成视频的主要平台有Pika、Runway Gen2等,但是这两个平台视频生成默认都是几秒中,即便通过视频扩展等手段,最多也只能生成十几秒的视频。而OpenAI的Sora可以生成最多1分钟的视频。并且视频生成的结果非常连贯和清晰。
这是OpenAI Sora另一个与此前视频生成平台有巨大差异的地方。基于已有视频继续扩展在Runway Gen2、Pika等平台都有。
但是现有平台的视频扩展通常是在当前视频的基础上继续向前生成几秒的视频。但是,OpenAI Sora可以在视频的基础上向前或者向后扩展。
例如给定一个视频,OpenAI Sora可以为该视频创造不同的开头,最后都是以该视频结尾,过程非常连续。因此,Sora甚至可以在一个视频上同时向前和向后扩展,以产生一个无限连续的循环视频。
根据OpenAI的Sora技术报告,Sora模型可以采样宽屏1920×1080视频、竖屏1080×1920视频以及介于两者之间的所有尺寸视频。
这意味着它可以生成更加自由的视频尺寸。而此前的视频平台,如Runway Gen2,文本生成视频的方式只能选择16:9, 9:16, 1:1, 4:3, 3:4, 以及 21:9的长宽比。至于清晰度,则默认1408 × 768px。
OpenAI Sora的能耐还不仅仅是“文生视频”。他还能把两个视频,揉捏在一起,实现无缝过渡。这也是Sora另一个与众不同的地方。
OpenAI发布了一份Sora的技术报告,在报告中提到“Sora是一个扩散模型”。

来源:OpenAI官网
此前,OpenAI的研究者一直在探索的一个难题就是,究竟怎样在视频数据上,应用大规模训练的生成模型?
为此,研究者同时对对持续时间、分辨率和宽高比各不相同的视频和图片进行了训练,而这一过程正是基于文本条件的扩散模型。
他们采用了Transformer架构,这种架构能够处理视频和图片中时空片段的潜代码。随之诞生的最强大模型Sora,也就具备了生成一分钟高质量视频的能力。
OpenAI研究者发现了令人惊喜的一点:扩展视频生成模型的规模,是构建模拟物理世界通用模拟器的非常有希望的方向。顺着这个方向发展,或许LLM真的能够成为世界模型!
Sora 不 足 之 处
虽然Sora展现出了强大的能力,但现阶段它还不够完美。
在Sora的技术报告中也承认,现阶段Sora生成的视频存在一些缺陷。比如,它虽然能模拟一些基础物理互动,比如玻璃的碎裂,但还不够精确。
视频中杯子还未破碎,液体就已流出,很明显能看出不是“真实事件”

模拟吃食物的过程,也并不总是能准确反映物体

最后,OpenAI表示,Sora目前所展现出的能力,证明了不断提升视频模式的规模是一个令人振奋的方向。沿这个方向走下去,或许在未来的某一天,世界模型真的应运而生。
关于Open AI发布的Sora,你有何看法?欢迎将你的想法留言给我们!
在这里向大家宣传一个好消息!当你还在为昂贵的显卡价格发愁的时候,算力云平台官宣了超低价活动!在2月底之前,全平台显卡享受75折优惠,包月套餐优惠力度最大,还为显卡发愁的用户赶紧来看看!