在2024年GTC人工智能大会上,英伟达再次燃爆全场,新一代性能“巨兽”Blackwell诞生!英伟达CEO黄仁勋宣布Blackwell B200 GPU和GB200(超级芯片)发布!定位直指“新工业革命的引擎” ,“把AI扩展到万亿参数”。堪称显卡界的新型核弹!
网友们纷纷惊叹,Blackwell再一次改变了摩尔定律。
去年,H100 GPU让英伟达超越谷歌、亚马逊成为全球市值第三大公司。但此次发布的B200 GPU能顶5个H100!
从2016年开始至今,AI算力已增长1000倍。黄仁勋认为「加速计算到达了临界点,通用计算已经过时了」。

「我们需要更大的GPU,如果不能更大,就把更多GPU组合在一起,变成更大的虚拟GPU」。
Blackwell新架构硬件产品线都围绕这一句话展开。

一个H100的晶体管数量是800亿,单个H100最多提供4 petaflops的FP4性能,而B200的晶体管数量是H100的2倍多,达到2080亿。B200 GPU从2080亿个晶体管中能提供高达20 petaflops的FP4性能,实现了5倍性能提升。
将两个B200与单个Grace CPU相结合后就是GB200超级芯片,可为LLM推理工作负载提供30倍的性能。
在GPT-3(1750亿参数)大模型基准测试中,GB200的性能是H100的7倍,训练速度是H100的4倍。成本和能耗最多可降低25倍!

与相同数量的72个H100相比,GB200 NVL72对于大模型推理性能提升高达30倍,成本和能耗降低高达25倍。若把GB200 NVL72当做单个GPU使用,具有1.4EFlops的AI推理算力和30TB高速内存。
这种处理能力,能让AI公司训练更大、更复杂的模型,甚至可以部署一个27万亿参数的模型。

全新芯片其中一个关键改进是,采用了第二代Transformer引擎。对每个神经元使用4位(20 petaflops FP4)而不是8位,直接将算力、带宽和模型参数规模提高了一倍。
英伟达同时还推出了第五代NVLink网络技术。最新的NVLink迭代增强了数万亿参数AI模型的性能,提供了突破性的每GPU双向吞吐量,促进了无缝高速通信。
另外,Blackwell还配备了RAS引擎。
为了确保可靠性、可用性和可维护性,Blackwell GPU集成了专用引擎和基于AI的预防性维护功能,以最大限度地延长系统正常运行时间并最大限度地降低运营成本。

此次大会,黄仁勋还提到了在2016年送出的OpenAI的DGX-1,那是史上第一次8块GPU连在一起组成一个超级计算机。从此之后便开启了训练最大模型所需算力每6个月翻一倍的增长之路。
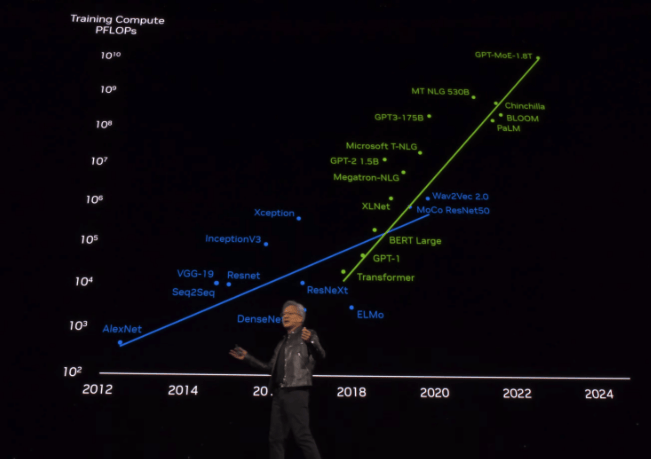
所以,GB200的成本是多少呢?虽然目前英伟达并未公布。
根据分析师估计,英伟达此前发布的H100芯片,每颗的成本在25,000美元到40,000美元之间,整个系统的成本高达200,000美元。而性能远超过H100的GB200价格是不可能低于H100芯片的。未来芯片性能增强,价格也基本呈上升趋势,“显卡普遍降价”的景象可以说5年内很难出现,不过现在国内的算力租赁平台已进入快速发展阶段,像算力猴、算力x平台也都被大众所认可,如果有算力需求但预算有限的用户,不妨先去官方渠道领取产品体验金额感受看看。
以上是算力云平台带来的内容。这次GTC大会亮点不断,你有什么感受呢?欢迎评论区互动留下你的观点。